TheoryHub: A Proposal for More Cumulative, Iterative, and Connected Theory-Building in Psychology
Establishing theories of this nature is perhaps the field’s greatest challenge. By some accounts the theory crisis is more fundamental than—and perhaps the very source of—the replication crisis1.
To call good theory-building difficult is an understatement. The social sciences must grapple with fundamental challenges: some causes are unobservable/unmanipulable internal or latent entities; humans are so complex that even our best models will only ever probabilistically determine outcomes, and incentive structures push scientists to have their own thing rather than iterate on someone else’s.
However, I nonetheless feel we can do better, and I have a proposal that can help us get there: TheoryHub. TheoryHub is an envisioned platform where, analogously to GitHub, researchers create and iterate on version-controlled theoretical models in the form of directed acyclic graphs2. By benefiting researchers with a clearer “menu” of testable hypotheses and benefiting the field with stronger links between studies and the underlying models and theories they purport to be testing, TheoryHub could support a psychological science that is as cumulative as it aspires to be.
This post is my attempt to work through ideas and solicit feedback. It’s structured as follows:
- Challenges inhibiting the development of strong, communal theory
- The structure of TheoryHub and illustrate its use with a toy example
- How TheoryHub can address the challenges identified in section 1
- Anticipated problems for a development and deployment of TheoryHub
Let’s dive in.
Challenges for Theory Development in the 21st Century
Problem 1: Vague, Verbal Theory
The problem of vague is not new, and has received much more coherent accounts than I can give.3 In short, however, researchers have for decades criticized the fact that theories are often stated in verbal terms, which leaves a very loose derivation chain4—there are a near-infinite set of ways that a researcher can instantiate that theory in the form of a statistical test, based on things like confounding (i.e., the other factors that may or may not be part of the causal structure) and measurement. When a study fails to find support for the theory, these results are often dismissed as illegitimate tests—if you had simply run the study how I (implicitly) understand the theory, you would’ve gotten a positive result, proponents may argue.
One common proposal to strengthen the derivation chain is to make greater use of Directed Acyclic Graphs (DAGs)—graphs consisting of nodes (variables such as psychological traits or environmental factors), connected by arrows, which signify directional causal effects. These graphs are ‘acyclic,’ such that causality flows in one direction only. Using DAGs, researchers can formally encode their causal assumptions or evidence.
Using DAGs is not a cure-all: first, theories are larger than a specific causal model (a theory may entail many or even infite infinite possible DAGs), and second, using a DAG does not constrain the universe of (non-)parametric models that could be used. As Eiko Fried (2020)5 wrote:
“models … are instantiations of theories, narrower in scope and often more concrete, commonly applied to a particular aspect of a given theory, providing a more local description or understanding of a phenomenon” (p. 336).
Nonetheless, using DAGs offers one way to make clearer progress in theory-building, by leveraging the clarity of formal diagrams while remaining mindful of the broader, often intricate, conceptual landscape. Also, I’m much more likely to give your paper a favorable review if you use one.
Problem 2: Static, “Owned Theories”
Eronen & Bringmann (2019)[^1] (and I believe Daniël Lakens before them, maybe in his MOOC) highlight a textbook containing 83 behavior change theories, writing “It is safe to assume that none of these theories is universally accepted or decisively refuted.”
Our field’s default is seemingly to birth theories and let them compete in a overwhelming battle royale, where they either survive or die as wholesale entities. We rarely modify and adapt them; they are generally proposed in one form by specific authors, and then fiercely debated until eventually something else comes along—sometimes because the new theory has better explanatory and predictive power, but just as often because people have gotten bored with the old theory (e.g., when its originators retire or move onto other topics).
“It is simply a sad fact that in soft psychology theories rise and decline, come and go, more as a function of baffled boredom than anything else; and the enterprise shows a disturbing absence of that cumulative character that is so impressive in disciplines like astronomy, molecular biology, and genetics” (Meehl, 1978, p. 807)6
Related to this point, we tend to view theories as “owned” by their originators—and often behave as though only those people have the right to modify or adapt them. However, it is almost impossible for the originators of a theory to be objective judges of the evidence for and against that theory—science is simply too personal, and the majority among us (myself very much included) would look a little more carefully at disconfirming evidence for their proposal than at confirming evidence. Eventually, perhaps, the evidence becomes overwhelming and one has no choice but to abandon the theory (see Michael Inzlicht’s blog for a personal account of this in the context of ego depletion). But in general, we should be skeptical of allowing a theory’s originators to be the sole stewards of its development and evidence synthesis. Theories are community resources, and perhaps our most valuable communal products.
Problem 3: Lacking feedback from empirical results
Closely related to the previous point is the disconnect between theory and their tests. When theoretical tests are conducted—especially when the testers are not the theory’s originators—their results are often never, or only very loosely used in the process of assessing or improving the theory.
Either we rely on a set of researchers—often the theory’s originators—to serve as constant watchdogs of the literature, hoping that over time their internal models will update in response to this evidence, and that they may ultimately proclaim a new version informed by all this work. Or perhaps with sufficient interest or time, empirical results may be included in a meta-analysis of a particular hypothesis and thereby contribute to a narrow attempt at falsification.
In both of these situations, however, it is very easy for empirical results to go missing (or, at minimum for them to be very laborious to detect and integrate), and testers’ alternative explanations, additions, subtractions, or other proposed adaptations for the theory are rarely seen and even more rarely directly incorporated back into the theory they were testing.
Problem 4: Too Much Science
The number of papers continues to rise, as researchers both gain new tools for accomplishing tasks efficiently, and operate under increasingly high standards for productivity to survive in a scientific career.
This ballooning literature makes it exceedingly difficult for a single researcher to stay abreast of all relevant results even within their own narrow field, much less in a more holistic view of psychology at large. Researchers must increasingly rely on heuristics for deciding which papers are actually worth reading or building upon. For some, that may be related to open science practices—which, as open science becomes ever more normalized, may no longer filter sufficiently. For others, it is personal—we trust papers written by people we know, or people who have been vouched for by trusted colleagues.
Regardless, it is clear that we need tools to structure the literature such that bodies of work are more coherently grouped, and more easily synthesized, to limit the waste that otherwise results from hundreds of thousands of papers whose results never have the opportunity to improve a communal output.
TheoryHub
In short, we have a situation where theories are (1) vague, (2) static, (3) lacking clear feedback mechanisms from empirical results, and (4) buried in an avalanche of literature no one can possibly stay on top of. This brings me to my proposal for TheoryHub.
Envisioned TheoryHub Structure
TheoryHub is envisioned as a version-control repository for theories and causal models. Its purpose is to:
- Provide a repository of clear, testable hypotheses from existing theoretical work, thus strengthening the derivation chain
- Allow researchers to “check out” a model or hypothesis from the theory bank, and link their empirical results directly to this theory in the form of a shortcode and by linking their results to the theory’s repository
- Allow researchers to “fork” a model, and propose a variation or update that they believe is more empirically validated, thus allowing for directly iterative and cumulative model and theory development
- With sufficient consensus, this forked version may eventually be “merged” back into the original version, thus ensuring continuity
I’ll use a simple model from a recent paper of ours to illustrate.
Step 1: Identify or create a theoretical umbrella under which to operationalize a model
As highlighted above, a single theory may entail many possible models, which need not necessarily be competing. We want models that share a conceptual basis to be organized accordingly, and so we group them under a theory. The theory itself may be defined verbally—as specifically as possible—so as to maintain generalizability7, or in the form of a more complicated model, such as a causal loop diagram8.
In a recent paper9, I developed the Basic Needs in Games (BANG) model of video games in mental health (which in turn sits under a larger umbrella of self-determination theory10). The causal loop diagram for this model looks like this.
Step 2: Specify and deposit a model in the form of a version-controlled Directed Acyclic Graph
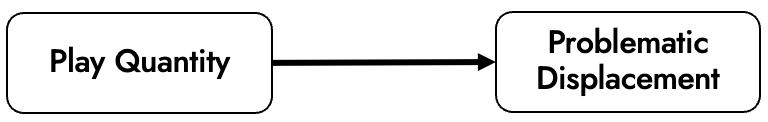
BANG entails a wide variety of causal predictions. Let’s say we’re interested in testing a small section of the wider theory: the relationship between play quantity (how much time people spend playing video games) and problematic displacement (a decrease in time allocated to health-relevant domains such as work/school due to the time spent playing games). The simplest possible version of this is visualized in Figure 1.
We thus deposit this extremely basic model into our TheoryHub repo. Each causal prediction in the DAG is given a code, for example in the form {theory}.{model}.{version}.{hypothesis}.—here, BANG.Displacement.v01.H1.
Step 3: Testers “check out” a model
At this point, the model is ready to be “checked out”—i.e., tested. Testers—whether the theory/model originators or not—can indicate that they are planning to test this particular model, or particular hypotheses within the model. In a preregistration or a manuscript, we would then see the code: we are interested in testing BANG.Displacement.v01.H1 (greater playtime causes greater problematic displacement).
Step 4: Deposit results
After conducting the study, the testers would then mark their test as complete, and provide a link to the results, or to a publication where the results are found. In a perfect world, they would also supplement their deposit with further details of the derivation chain: what measures they used, the timescale, the population, and so on.
In this case, let’s say we found a trivial, but significant correlation between playtime and problematic displacement: r = .10, 95% CI [.05, .15].
By linking their results to the checked-out model, the researchers form clear and obvious links between a specific model that may have predated the paper in which it was tested and the empirical results from testing it.
Step 5: Optionally, testers “fork” the theory
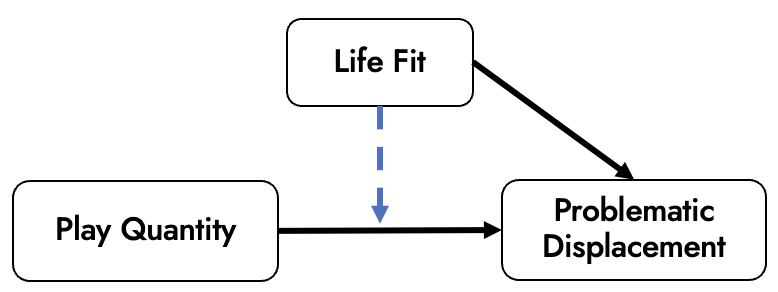
Let’s say however, that we conduct a further exploratory analysis whereby we assess potential moderation (effect size modification) based on life fit: people’s ability to successfully arrange their schedule to accommodate gaming-related leisure time, for example by completing their household responsibilities in advance.
As a tester of the BANG model, we may therefore “fork” the model on TheoryHub, and create a version v02 that we believe better captures the true state of the world: BANG.Displacement.v02-01, visualized in Figure 2: offer an alternative explanation (either purely hypothetical, or perhaps validated to some extent in an exploratory analysis).
Step 6: Repeated Testing
The next researchers that are interested in this model—whether the originators or otherwise—will now see two competing versions of it, v01 and v02. These subsequent testers may make a judgement call about which version is better-aligned with their understanding or predictions and choose to test or build upon that version. They may also wish to conduct an adversarial test—which of v01 and v02 better accounts for the data in our sample?
Step 7: Evidence synthesis
In open source software development, there are often many people responsible for the development and maintenance of a tool—many of whom may have had no role in its initial creation. Instead, a community of engaged supporters of the tool collaboratively and flexibly delegate responsibilities, reach consensuses, and act as collective stewards of an important communal resource.
My proposal for TheoryHub is similar. People who demonstrate strong knowledge of the theory may request to join the maintenance team. Over time, a theory may thus develop a team of stewards, who act collectively to maximize the theory’s alignment with the empirical world and value to the wider community.
In our example, the maintenance team may decide after a few successful tests that the version with the confound is better aligned with a growing evidence base, decide to endorse BANG.Displacement.v02-01 as the “canonical” model. In GitHub terms, this acts as a merge or a “pull request”—we begin with both v01 and v02, and eventually select one of the two (or potentially a combination of them) that we believe is the best current version, and thus return to a single model with the greater consensus.
Benefits of TheoryHub
I hope this illustration has been clear, and I also hope it’s clear why I think this could help psychological science:
- Reduced translation gap: rather than needing to interpret a verbal theory and instantiate their own, ad hoc statistical model for a particular study, researchers will now have access to specific testable predictions “off the shelf.” While researchers still maintain the freedom to register their own competing theory or model, TheoryHub provides the option to directly build on previous work with clear guidance/constraints on measurement and statistical modelling
- Living systematic review: as empirical results will now have a direct connection to the models they are testing, we can much more easily synthesize the body of evidence on a topic, possibly on an ongoing basis—without relying on laborious and fraught systematic literature searches collated by a single research team.
- Incremental complexity: As I discovered all too well in my own thesis, trying to capture the full complexity of a (social) psychological system in a theory is extraordinarily difficult. No researcher can hold all of this complexity in their head, and no manuscript can hold it in its text, so we instead tend to use abstracted, simplified forms. TheoryHub would provide the scaffolding to begin with a simplified theory, but incrementally build up into the true complexity of the world (as visually overwhelming as it might ultimately be!)
TheoryHub is well aligned with a platform like Octopus, which supports the “publication” of a hypothesis by itself, and allows others to cite that hypothesis in subsequent tests. The key addition here is the GitHub-like version-controlling of these hypotheses and the focus on cumulative and community-guided iteration on these hypotheses.
Barriers and Open Questions
- DAGs are just one initial step towards more rigorous theory—tremendous effort is also going into computational modelling and so-called formal theory, specified at the level of an equation. In a distant future, I can imagine a version of TheoryHub where people are checking out theories at the level of parameter estimates and equations, and collaboratively working to refine them.
- As shown in Figure 2, DAGs struggle to encode effect size modification, something that is vital for many theories. A careful balance will be needed to ensure that causal models are sufficiently detailed to constrain the possible scope of analyses, but sufficiently generalizable to capture the full breadth of theoretical predictions common in the discipline
- Collaborative maintenance and stewardship is both a substantial undertaking (meaning that it would need to be incentivized under hiring and promotion criteria to justify people’s time and effort)
Closing Thoughts
TheoryHub is a fledgling idea, and there would be tremendous challenges in building such a platform, convincing people to use it, and ensuring that it supports the kinds of outcomes the psychology community wants. However, I think widespread adoption of the kind of theory-focused and community-owned iterative science that something like TheoryHub is trying to support would have a transformative impact on the field. I believe we would get more value out of the studies we conduct, and have more concrete and useful guidance to share with the public our field purports to serve.
-
Eronen, M. I., & Bringmann, L. F. (2021). The Theory Crisis in Psychology: How to Move Forward. Perspectives on Psychological Science, 174569162097058. https://doi.org/10.1177/1745691620970586 ↩︎
-
Rohrer, J. M. (2018). Thinking Clearly About Correlations and Causation: Graphical Causal Models for Observational Data. Advances in Methods and Practices in Psychological Science, 1(1), 27–42. https://doi.org/10.1177/2515245917745629 ↩︎
-
Oberauer, K., & Lewandowsky, S. (2019). Addressing the theory crisis in psychology. Psychonomic Bulletin & Review, 26(5), 1596–1618. https://doi.org/10.3758/s13423-019-01645-2
Eronen, M. I., & Bringmann, L. F. (2021). The Theory Crisis in Psychology: How to Move Forward. Perspectives on Psychological Science, 174569162097058. https://doi.org/10.1177/1745691620970586 ↩︎
-
Scheel, A. M., Tiokhin, L., Isager, P. M., & Lakens, D. (2021). Why Hypothesis Testers Should Spend Less Time Testing Hypotheses. Perspectives on Psychological Science, 16(4), 744–755. https://doi.org/10.1177/1745691620966795 ↩︎
-
Fried, E. I. (2020). Lack of Theory Building and Testing Impedes Progress in The Factor and Network Literature. Psychological Inquiry, 31(4), 271–288. https://doi.org/10.1080/1047840X.2020.1853461 ↩︎
-
Meehl, P. E. (1978). Theoretical risks and tabular asterisks: Sir Karl, Sir Ronald, and the slow progress of soft psychology. Journal of Consulting and Clinical Psychology, 46(4), 806–834. https://doi.org/10.1037/0022-006X.46.4.806 ↩︎
-
Sanbonmatsu, D. M., Neufeld, B., & Posavac, S. S. (2025). There is no theory crisis in psychological science. Journal of Theoretical and Philosophical Psychology. https://doi.org/10.1037/teo0000301 ↩︎
-
Crielaard, L., Uleman, J. F., Châtel, B. D. L., Epskamp, S., Sloot, P. M. A., & Quax, R. (2024). Refining the causal loop diagram: A tutorial for maximizing the contribution of domain expertise in computational system dynamics modeling. Psychological Methods, 29(1), 169–201. https://doi.org/10.1037/met0000484 ↩︎
-
Ballou, N., & Deterding, S. (2024). The Basic Needs in Games Model of Video Game Play and Mental Health. Interacting with Computers, iwae042. https://osf.io/6vedg. https://doi.org/10.1093/iwc/iwae042 ↩︎
-
Ryan, R. M. (Ed.). (2023). The Oxford Handbook of Self-Determination Theory (1st ed.). Oxford University Press. https://doi.org/10.1093/oxfordhb/9780197600047.001.0001 ↩︎